This document briefly describes the AMR-related features in BHAC inherited from MPI-AMRVAC. The different options can be set in the &amrlist of the amrvac.par file. For a more extensive description, you can read the article `Parallel, grid-adaptive approaches for relativistic hydro and magnetohydrodynamics', R. Keppens, Z. Meliani, A.J. van Marle, P. Delmont, A. Vlasis, & B. van der Holst, 2011, JCP. doi:10.1016/j.jcp.2011.01.020.
MPI-AMRVAC uses a standard block-based, octree AMR scheme, where we have blocks of user-controlled dimension (set by the script $BHAC_DIR/setup.pl -g=) in a hierarchically nested manner. To simplify the parallelization, the resolution jump between two AMR-levels is fixed to factors of two. Also, we now use the same time step for all levels. A generic skeleton code, generic enough to hold for any AMR code having similar restrictions, is shown below (in the subroutine terminology of MPI-AMRVAC it is shown here, where it corresponds with timeintegration).
Some more info follows on the different aspects involved.
This in essence describes the module errest.t, or at least its most essential aspets.
The block-tree nature implies that a decision for refining/coarsening is to be made on a block-by-block basis. This automated block-based regridding procedure involves these steps:
(1) consider all blocks at level 1< l< mxnest , with mxnest the maximal grid level selected; (2) quantify the local error E_\xx at each gridpoint in a certain grid block; (3) if any point has this error exceeding a user-set tolerance tol(l), refine this block (and ensure proper nesting); (4) if all points have their error below a user-set fraction of the tolerance tolratio(l) used in the previous step, coarsen the block (for l>1).The local error is selected by errorestimate, each possibly augmented with user-defined criteria. Any of these estimators use a user-selected subset of the conserved or auxiliary variables (or even variables that are computed dynamically at the time of regridding), through the formula
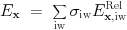
The setting errorestimate=1 represented the Richardson error estimator which is now discontinued though. We recommend the Lohner estimator (described below) for almost any situation.
For errorestimate=2, a local comparison merely employs the availability of the t^{n-1} and t^n solution vectors. It estimates the local relative variable errors as
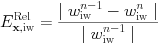
For errorestimate=3, is the Lohner [R. Lohner, An adaptive finite element scheme for transient problems in CFD, Comp. Meth. App. Mech. Eng. 61, 323 (1987)] prescription as adjusted in the PARAMESH library or the FLASH3 code. In our experience, it does not require any of the buffering just discussed, and is computationally efficient as it employs only instantaneous values from t^n. It in essence discretizes a weighted second derivative in each grid point. In formulae,
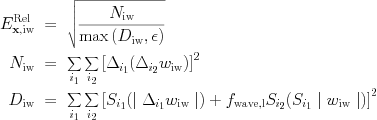
The data structures are defined in mod_physicaldata.t and mod_forest.t, you can inspect them for learning more details.
We provide details on useful data structures. All of these are suited for any curvilinear coordinate system, and merely reflect the tree structure of the block-AMR. We implicitly assume a fixed refinement ratio of two. Schematic figures for a 2D Cartesian case generalize straightforwardly to higher or lower dimensionality.
The overall domain is considered `rectangular', i.e. bounded by coordinate pairs xprobmin1,xprobmax1, ... in each dimension. On the lowest grid level l=1, one controls the coarsest resolution as well as a suitable domain decomposition, by specifying both the total number of level 1 grid cells nxlone1, ... along with the individual block size per dimension (this is done by $BHAC_DIR/setup.pl -g=, which includes the ghost cells, a layer of width dixB). The total cell number must be an integer multiple of the block size, so e.g. nxlone1=20 and dixB=2 for a 1D case requires setamrvac -g=14, which creates two grids of size 10 on level one each having a total of 4 ghost cells (2 on each side, hence 14).
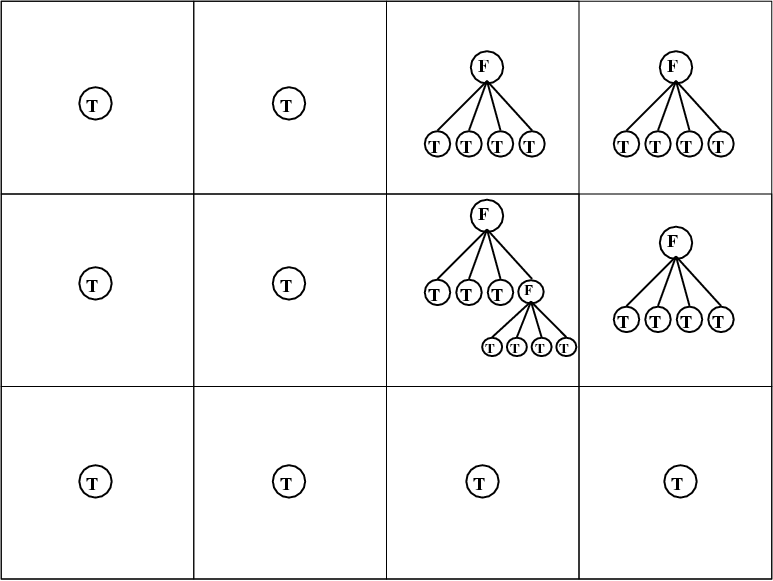
A hypothetical 2D domain is shown below, which corresponds to a domain where 4 by 3 blocks on level 1 are exploited in this domain decomposition, and where local refinement was activated in 4 out of these level l=1 blocks, here in the top right domain corner, as well as in one level l=2 grid.
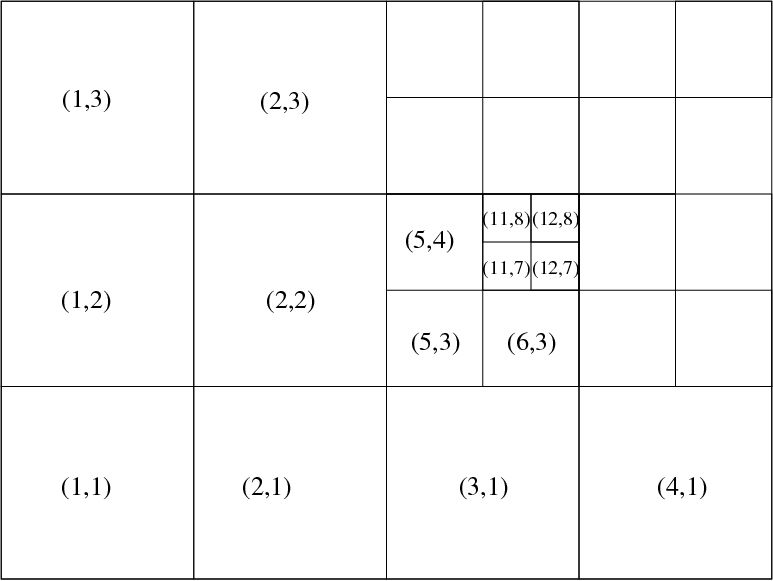
The bottom figure reflects the tree representation of the same hypothetical grid hierarchy, where the presence of a grid leaf at a certain grid level is identified through a boolean variable. As indicated before, the total number of active grid leafs nleafs may change from timestep to timestep. This tree info is stored in the structure tree_root(ig^D(l)), which knows about the global grid index through tree_root(ig^D(l))%node%ig^D, the level tree_root(ig^D(l))%node%level, the processor on which it resides through the integer tree_root(ig^D(l))%node%ipe, and its presence or absence in the logical tree_root(ig^D(l))%node%leaf.
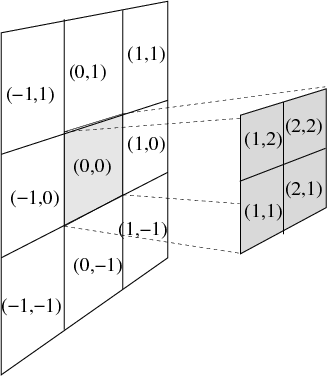
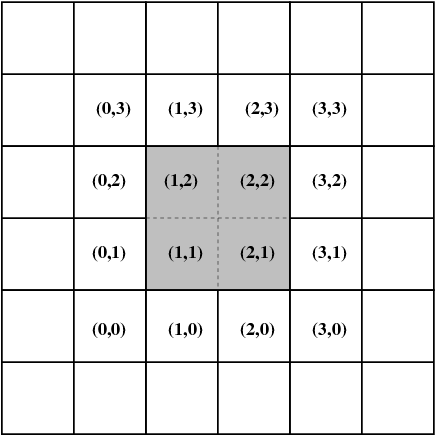
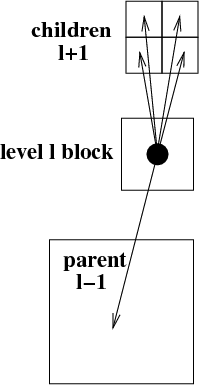
Various extra indices are helpful to traverse the tree structure. Local grid indices across AMR levels are schematically given below, which are used to identify the directional neighbours, as well as the children and parent blocks. These are used to realize and facilitate the possible interprocessor communication patterns, which are schematically shown at right.
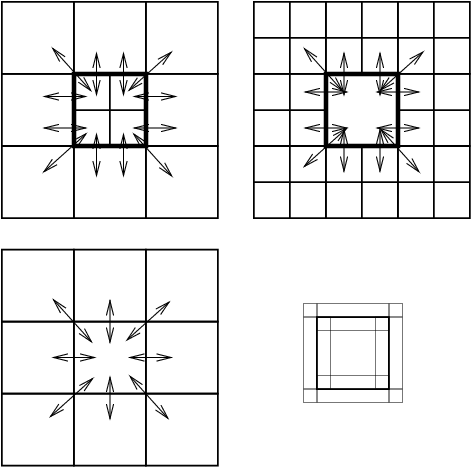
The directional neighbours of a grid block are shown for a 1D, 2D and 3D case in the picture below.
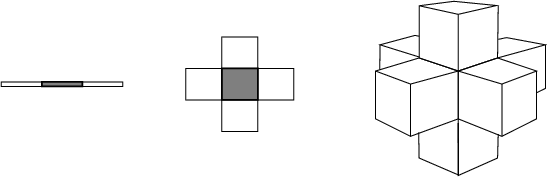
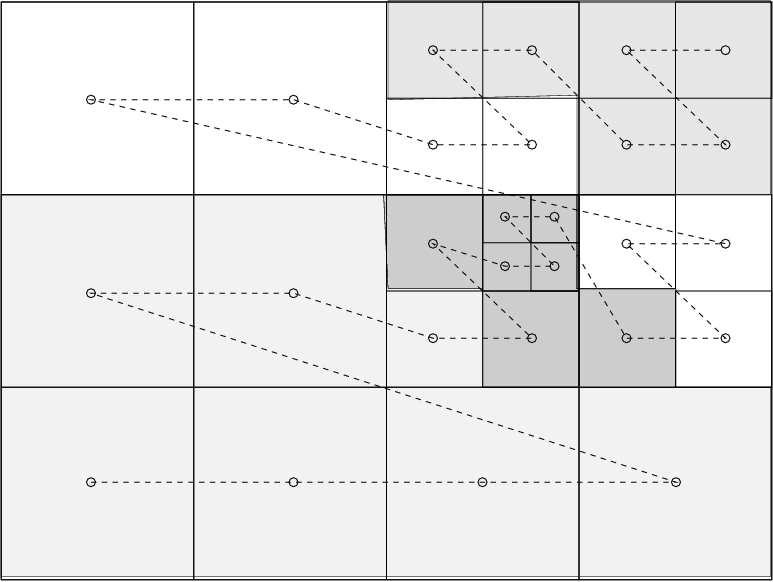
For parallelization, we adopted a fairly straightforward Z-order or Morton-order space filling curve. For the same hypothetical grid structure shown previously, the Morton space-filling curve is illustrated below, along with the resulting distribution of these 27 grid blocks on 4 CPUs. Load-balancing is done after every timestep, following the adaptive remeshing. When exploiting N_p CPUs, our strategy for load balancing merely ensures that each CPU has at least [nleafs/N_p]_int (denoting integer division) grid blocks, while the remainder increase this number by 1 for the first as many CPUs. In the example shown, this implies that the first 3 CPUs each contain 7 grid blocks, while the fourth has 6. The grid Morton numbers of all grids residing on processor mype lie between Morton_start(mype),Morton_stop(mype). The global grid index, once you know the grid Morton number Morton_no is found from sfc_to_igrid(Morton_no), which gives the relation between the Space Filling Curve (sfc) and the global grid index igrid. The data for the conservative variables for grid igrid is then actually found from pw(igrid)%w.
Some operations benefit from having a linear, linked list possibility to traverse the tree on a level by level basis. To that end, each grid also contains a pointer to the previous and next grid created in the same AMR level, taking all grids on all processors into account. This linked list is complemented with a globally known pointer to the first (head) and last (tail) grid on each level. For the hypothetical grid structure used above, this corresponding linked list representation is shown next.